Prove sorprendenti suggeriscono che BioNTech/Pfizer ha falsificato dati chiave e ulteriori scandali (parte 2)

Pubblicato originariamente su Trial Site News
Parte 1 del mio rapporto investigativo pubblicato su Trial Site News incentrata sugli insoliti “Western Blot” di Pfizer-BioNTech – lo scandalo noto come Blotgate. I Western Blot sono stati condotti da BioNTech per dimostrare la fedeltà del loro prodotto (alle autorità di regolamentazione), ovvero che solo la proteina spike prevista veniva espressa in vitro dall’mRNA vaccinale modificato ed era coerente tra i diversi lotti.
Il problema del fatto che non sembrino Western blot autentici/convenzionali, ma piuttosto versioni generate al computer (Western blot automatizzati, nonostante non siano etichettati come tali in nessuno dei rapporti), è una distrazione dal vero scandalo in questione: le prove, che dimostrano prima facie che BioNTech/Pfizer ha “copiato e incollato” queste bande, in altre parole, ha falsificato i suoi dati chiave. Queste bande Western apparentemente falsificate (illustrate di seguito) sono state presentate nella risposta di Pfizer alle richieste della Food and Drugs Administration statunitense intorno al novembre 2020, nel periodo precedente l’autorizzazione all’uso di emergenza.
Solo quando queste bande sono state quantificate con l’ausilio di un software di analisi delle immagini (grazie a un esperto anonimo), il lavoro di “copia e incolla”, condotto su 4 lotti separati del loro prodotto, trasfettati a 6 diverse concentrazioni, è diventato sorprendentemente visibile.
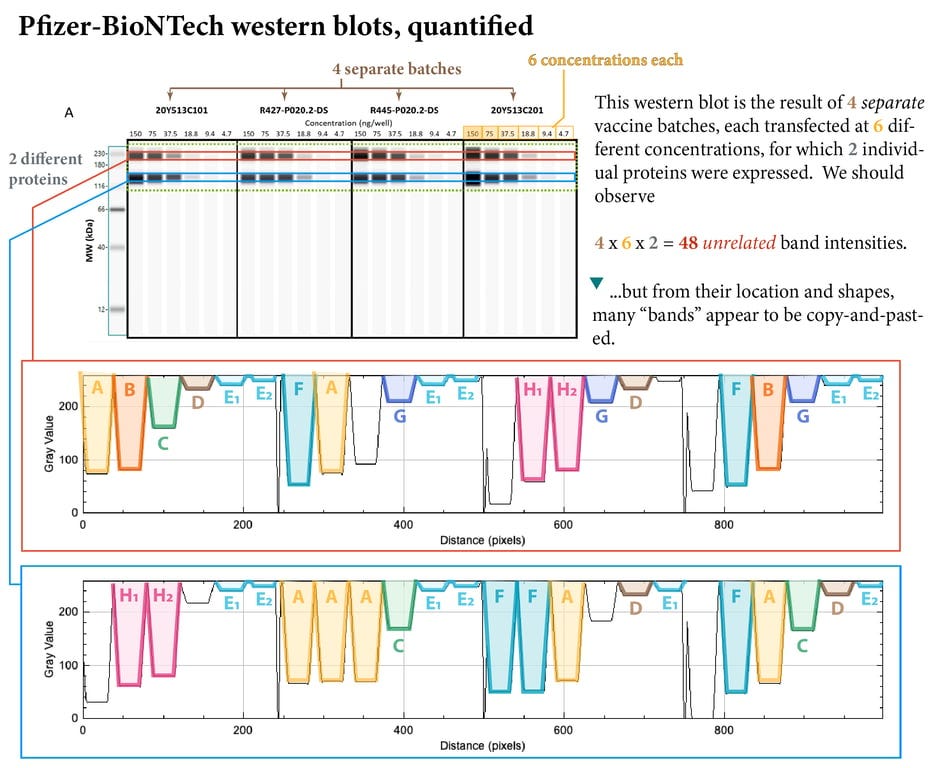
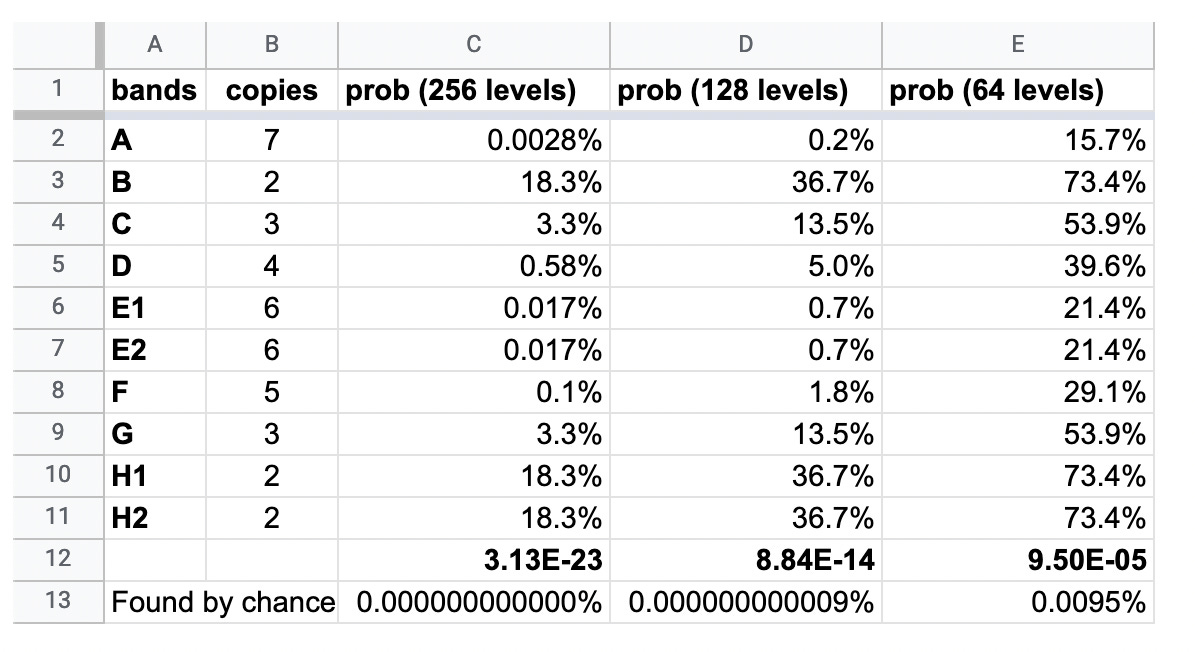
Le probabilità che queste stesse bande si presentino naturalmente in quattro lotti separati del vaccino, trasfettati a 6 diverse concentrazioni, sono riportate nella tabella sottostante.
Sulla scia della prima parte del mio rapporto investigativo, Epoch Times ha condotto una propria indagine sul Blotgate, sui problemi di qualità dell’mRNA del vaccino Pfizer-BioNTech e ha fatto riferimento all’indagine di Trial Site News sulle e-mail e sui documenti dell’Agenzia Europea dei Medicinali (EMA) trapelati.
nascondere le bande sporche”: un ulteriore sguardo al Blotgate
Il 13 gennaio, poco dopo lo scoppio dello scandalo Blotgate, l’articolo di Patel et al. sponsorizzato da Pfizer e BioNTech “Characterization of BNT162b2 mRNA to Evaluate Risk of Off-Target Antigen Translation” è stato pubblicato su nel Journal of Pharmaceutical Sciences. L’articolo presenta molte anomalie e vale la pena di notare che la dottoressa Jessica Rose, biologa computazionale e molecolare, ha scritto un’analisi critica completa di questo studio.
In primo luogo, vale la pena di notare gli interessi in competizione degli autori, che si possono vedere qui sotto.

Parlando con la dott.ssa Jessica Rose, che ha effettuato numerosi Western Blot convenzionali, ha spiegato: “Secondo la mia opinione di esperta, [un Western tradizionale] è uno dei test da banco che è una procedura, come i test di sicurezza per i biologici (che dovrebbero durare 10 anni). Un western blot richiede una sequenza di passaggi specifici, questi passaggi non possono essere affrettati e non possono essere sovrapposti… gli esperimenti eseguiti con Robo Jess [macchina automatica per western blot] e i blot presentati da Pfizer devono essere riprodotti da mani umane, la riproducibilità è un requisito soprattutto quando l’elenco dei conflitti di interesse è così lungo da parte degli autori che hanno presentato il lavoro [Patel et al.]
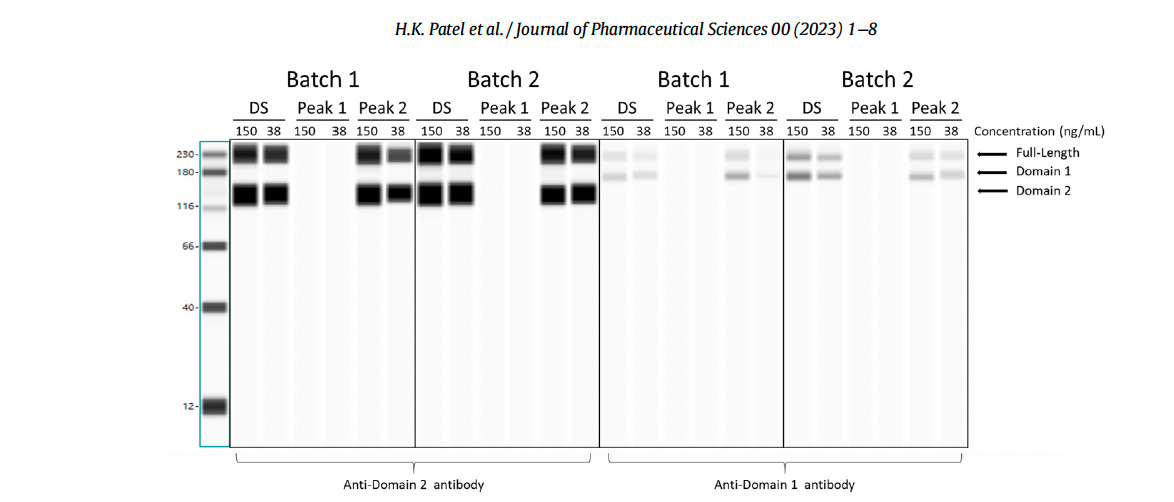
L’immagine sottostante, tratta dall’articolo di Patel et al. mostra il loro “Western Blot” Si notino le bande nere regolari molto spesse (omogenee) senza alcuna sbavatura.
Lo stesso “Western Blot” (visto sotto), ma in una versione molto più cruda e scannerizzata, si trova nel rapporto dell’Agenzia Europea per i Medicinali CHMP (Committee for Medicinal Products for Human Use) dell’agosto 2021, redatto circa 18 mesi prima dell’articolo di Patel et al.
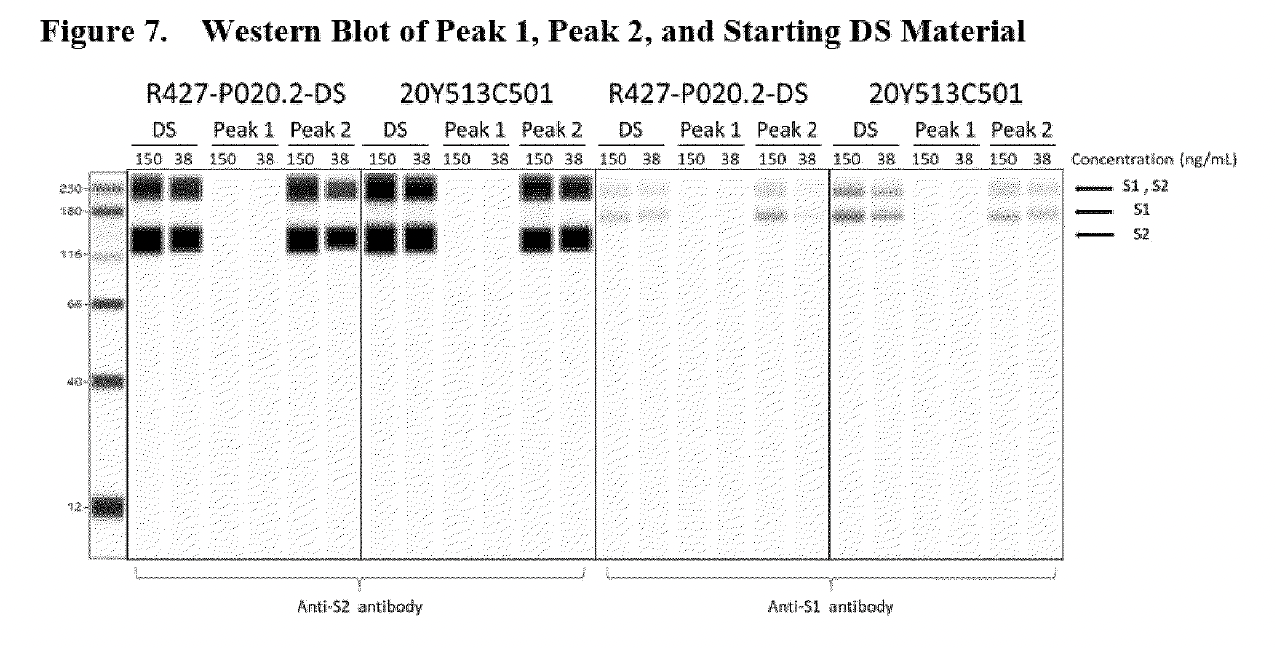
Poiché gli autori di Patel et al. fanno riferimento alla tecnologia di ProteinSimple nel loro studio (estratto sotto), è possibile fare un confronto con un campione di Western Blot automatizzato, utilizzando il software della stessa azienda.
i lisati cellulari sono stati analizzati con gli anticorpi specifici per rilevare le proteine spike del SARS-CoV-2 utilizzando la tecnologia ProteinSimple. sono stati utilizzati il modulo di separazione Wes 12-230 kDa e 25 cartucce capillari. Sono stati utilizzati l’anticorpo di topo SARS-CoV-2 Spike S1 subunit (R&D systems, numero di catalogo MAB105403) e l’anticorpo di topo SARS-CoV-2 Spike S2 subunit (R&D systems, numero di catalogo MAB10557). I risultati dei campioni di mRNA sono riportati come immagini della corsia di esecuzione del saggio ProteinSimple Wes.’
Fonte: Documento di Patel et al
L’immagine sottostante mostra un Western automatizzato utilizzando la tecnologia di ProteinSimple.
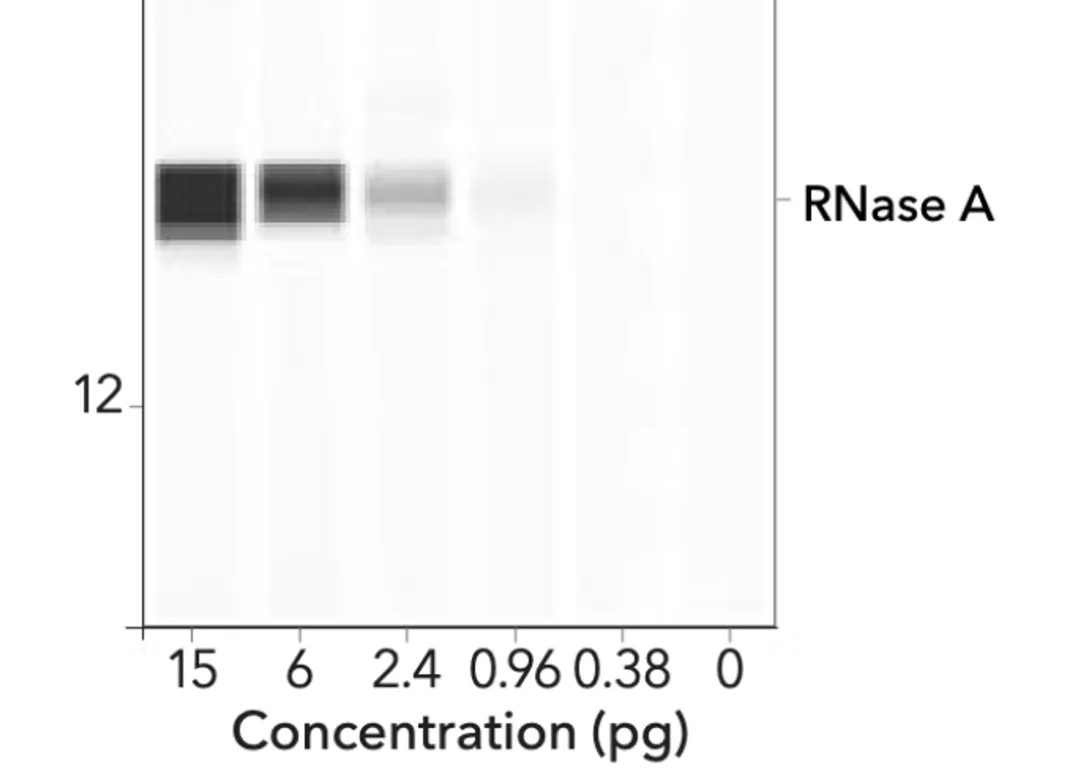
Ciò che colpisce è che si può osservare un gradiente (effetto spalmato) in ciascuna delle varie bande. Il loro aspetto è molto diverso da quello delle bande omogenee nere e spesse di BioNTech/Pfizer.
Per saperne di più, ho intervistato il responsabile della ricerca e sviluppo del Progetto Genoma Umano e scienziato genomico, Kevin McKernan, il quale ha spiegato che i “dati di BioNTech/Pfizer sono inutilizzabili” e che il suo ragionamento per l’aspetto insolito delle bande del Western Blot (che si vede nel rapporto dell’EMA e nel documento di Patel) è dovuto al fatto che “loro [BioNTech] hanno aumentato così tanto il guadagno e la maggior parte delle persone lo fa per nascondere le ‘bande sporche’ Probabilmente ci sono 5 bande lì dentro [in un’unica banda spessa]” Faccio riferimento a questa intervista informativa, più avanti in questa relazione.
Ciò fa sorgere la domanda: BioNTech/Pfizer ha forse insabbiato intenzionalmente i risultati dei propri “Western blot” presentando versioni manipolate (di Western automatizzati) alle autorità di regolamentazione? Forse un lavoro di copia e incolla per la FDA e una manipolazione dei livelli di saturazione per l’EMA? E soprattutto: come hanno fatto gli enti regolatori ad accettare questi “Western blot” come prova principale per dimostrare la fedeltà e la coerenza del prodotto di BioNTech e Pfizer?
Ho contattato l’EMA per avere una risposta in merito alle preoccupazioni sollevate in questa indagine. L’addetto stampa ha risposto con la seguente dichiarazione: “Queste figure [immagini di Western Blot] sono state estratte dal dossier presentato e inserite nel rapporto di valutazione, con conseguente perdita di qualità dell’immagine. Inoltre, il software di redattazione utilizzato dall’EMA per preparare i documenti da rilasciare a seguito di una richiesta di ATD ha un impatto sulla risoluzione dei documenti”.
Per quanto riguarda la convalida dei metodi, i metodi analitici Western Blot utilizzati negli studi di caratterizzazione sono stati precedentemente valutati durante la domanda iniziale di autorizzazione all’immissione in commercio condizionata come parte della “storia dello sviluppo e della valutazione della comparabilità” e sono stati considerati adeguati a tale scopo
L’FDA, Pfizer e BioNTech non hanno risposto ai commenti.
Parametri di qualità fissati mesi dopo la concessione dell’autorizzazione all’immissione in commercio
Il motivo per cui il titolare dell’autorizzazione all’immissione in commercio (BioNTech) ha condotto un’ulteriore serie di test è che l’autorizzazione all’immissione in commercio condizionata (CMA) è stata concessa sulla base dell’adempimento da parte del titolare dell’autorizzazione all’immissione in commercio di obblighi specifici (ad esempio, dati aggiuntivi per caratterizzare ulteriormente le specie di mRNA troncate e modificate) imposti dall’EMA. Fino al momento in cui è stata concessa l’autorizzazione all’immissione in commercio, l’EMA ha segnalato diversi problemi di CMC (chimica, produzione e controllo), in particolare il calo dell’integrità dell’mRNA (presenza di mRNA troncato/frammentato – privo di un attributo critico, il 5’cap e/o la coda di poli (A)) dei lotti commerciali rispetto a quelli utilizzati negli studi clinici. La “soluzione” a questo grave problema è stata l’abbassamento dei criteri di accettazione delle specie di mRNA frammentate/truncinate al 50%, a cui le autorità di regolamentazione hanno semplicemente rinunciato.
La farmacista canadese Maria Gutschi, PharmD, con oltre 30 anni di esperienza in ambito ospedaliero, comunitario e governativo, ha analizzato in modo indipendente i problemi di qualità del vaccino Pfizer/BioNTech identificati dall’Agenzia Europea dei Medicinali, in un video di presentazione informativo. Parlando con Gutschi, ha sollevato altre importanti preoccupazioni: solo nel maggio 2021 [5 mesi dopo l’autorizzazione] l’OCABR ha stabilito i parametri di qualità e, soprattutto, la standardizzazione dei test utilizzati. Un problema che ho riscontrato è che al momento del lancio, molti dei test utilizzati per determinare la qualità e l’identità erano test “interni” di BioNTech. Ebbene, un’autorità di regolamentazione non può semplicemente accettarlo. Devono essere convalidati in modo da essere coerenti, riproducibili e affidabili“
OCABR è l’acronimo di Official Control Authority for Batch Release (Autorità ufficiale di controllo per il rilascio dei lotti), che stabilisce le linee guida per i vaccini umani autorizzati nell’UE. Si noti l’evidenziazione della data del maggio 2021 del documento dell’OCABR, riportata di seguito.

Il fatto che l’OCABR abbia stabilito i primi parametri di qualità di un vaccino umano, ben 5 mesi dopo la concessione della CMA, non ha precedenti. In secondo luogo, è degno di nota il fatto che questi saggi (test) dovevano essere convalidati.
I discutibili test “in house
Vale la pena notare che la preoccupazione di Gutschi per i test “interni” di BioNTech è stata condivisa anche da un valutatore dell’EMA nel rapporto di revisione periodica del relatore trapelato nel novembre 2020, poco prima della concessione dell’autorizzazione all’immissione in commercio.

Nel documento di orientamento della FDA del 2016 su “Integrità dei dati e conformità alle CGMP” si legge che: ‘Negli ultimi anni, la FDA ha osservato sempre più spesso violazioni delle CGMP che riguardano l’integrità dei dati durante le ispezioni CGMP. Ciò è preoccupante perché garantire l’integrità dei dati è una componente importante della responsabilità dell’industria di assicurare la sicurezza, l’efficacia e la qualità dei farmaci e della capacità della FDA di proteggere la salute pubblica”
Il fatto che la FDA consideri “preoccupanti” le violazioni dell’integrità dei dati sembra svanire con la sua pronta accettazione dei dati apparentemente “copiati e incollati” della BioNTech. Forse si trattava solo di un esercizio di spunta per apparire come se stessero facendo la loro dovuta diligenza nel “proteggere la salute pubblica”
Le bande “inaspettate” mostrate nei Western blot autentici di BioNTech
Tra tutti i “Western blot” generati al computer, BioNTech ha effettivamente presentato due Western autentici (il secondo sarà discusso più avanti), che dimostrano che sapevano come farli. Nel rapporto di valutazione del Rapporteur’s Rolling Review dell’EMA trapelato, sono state mosse le seguenti critiche allo studio 20-0211 della BioNTech “per quanto riguarda i risultati ottenuti dal Western Blot”, riportati di seguito.

Lo scorso febbraio, lo studio 20-0211 (lo studio specificato sopra) condotto da BioNTech è stato reso pubblico come parte del dump di dati ordinato dal tribunale di Pfizer. Il Western Blot autentico altamente rivelatore mostrato in quello studio può essere visto qui sotto.

Dal rapporto di valutazione dell’EMA del novembre 2020, sappiamo che l’agenzia ha segnalato i pesi molecolari inattesi (misurati in kDa) delle due bande proteiche mostrate nel test Western Blot, rispettivamente di 190 kDa e 100 kDa, inducendola a chiedere spiegazioni a BioNTech. Ora, la proteina spike completa ha un peso molecolare di 141kDa e S1 (subunità della proteina spike) ha un peso molecolare di 76,5 kDa, che è stata usata come controllo. Dalla figura precedente si nota che nella corsia BNT 162B2 non sono presenti bande proteiche con i pesi molecolari previsti e che il peso molecolare previsto di 76,5 kDa della proteina S1 non è stato rilevato nella corsia di controllo S1. Queste anomalie sono state notate dal regolatore, ma in qualche modo lo sviluppatore del vaccino, BioNTech, che sicuramente avrebbe dovuto conoscere il peso molecolare atteso della proteina spike completa, dal momento che il suo prodotto mRNA dovrebbe codificare per essa, non le ha nemmeno riconosciute.
Per aggravare il loro completo fallimento nell’affrontare questi problemi, la BioNTech ha scritto una descrizione altamente imprecisa del loro Western Blot, di fatto l’esatto opposto di quanto mostrato nell’immagine: bNT162b2 ha una dimensione prevista di 141,14 kDa” e “la proteina della subunità S1 del SARS-CoV-2 (76,5kDa) è stata usata come controllo positivo”
Ciò suggerisce che forse la proteina spike S1S2 non è stata espressa dall’mRNA vaccinale modificato o, se lo è stata, forse sono state espresse anche altre proteine aberranti, derivanti da molecole di RNA frammentate/truncanti nella sostanza farmacologica.
Assenza di sequenziamento del genoma e problemi con la metilpseudourina N1
Interrogato sui problemi di qualità del vaccino Pfizer-BioNTech, lo scienziato di genomica Kevin McKernan ha fornito la seguente risposta:
‘Non abbiamo alcun sequenziamento del DNA su questi lotti. È assolutamente folle! Venendo dal progetto sul genoma umano, pubblicavamo una sequenza ogni 24 ore per assicurarci che il mondo avesse accesso agli ultimi dati emersi dal progetto sul genoma umano. Oggi non è possibile trovare alcun sequenziamento del genoma dei lotti“
È stupefacente che le autorità di regolamentazione si siano affidate a questi Western blot dall’aspetto manipolato della BioNTech, invece di richiedere sequenze genomiche dei lotti per dimostrarne la coerenza e la fedeltà”.
McKernan ha poi fatto riferimento ai problemi causati dall’RNA modificato sintetizzato utilizzando una base modificata: “Abbiamo un prodotto mRNA in cui ogni singola uridina è stata sostituita con N1 metilpseudourina, che l’organismo non ha mai visto prima. Loro [BioNTech e Pfizer] hanno scelto i codoni di stop che sono i più noti per creare errori. Erano consapevoli del problema, ma non lo hanno risolto correttamente. Ciò significa che quando i ribosomi vanno a leggere il modello, sono davvero confusi perché non l’hanno mai visto prima”
McKernan ha scritto insieme ai dottori Peter McCullough e Anthony Kyriakopoulos un articolo intitolato “Differenze nell’mRNA derivato dalla replicazione del vaccino e del SARS-CoV-2: Implicazioni per la biologia cellulare e le malattie future” Gli autori hanno concluso che “le modifiche dei codoni sinonimi incorporate nei vaccini a base di mRNA possono alterare la conformazione proteica codificata prevista, poiché la velocità e l’efficienza di traduzione possono portare a un ripiegamento proteico diverso… Le strategie di ottimizzazione dei codoni per lo sviluppo di vaccini a base di mRNA possono causare disregolarità immunitarie, influenzare la regolazione epitrascrittomica e portare alla progressione della malattia”
L’uridina modificata (N1 metilpseudorina) è stata incorporata nell’mRNA per eludere la risposta immunitaria innata e promuovere la traduzione delle proteine. Tuttavia, nel rapporto di Rolling Review dell’EMA del novembre 2020 (pagina 61), è stato sollevato un potenziale rischio per la sicurezza dell’RNA modificato (modRNA), vedi sotto.
il modRNA contiene una sostituzione di 1-metil-pseudouridina con uridina. Questa sostituzione diminuisce il riconoscimento dell’RNA del vaccino da parte dei sensori immunitari innati”. Tuttavia, non è stata fornita alcuna ulteriore discussione sul rischio di risposte autoimmuni indotte dal modRNA. Il Richiedente è invitato a discutere ulteriormente la possibilità che il vaccino a base di mRNA possa innescare potenziali risposte autoimmuni e come pensa di valutarne l’eventuale insorgenza
Non è noto se la BioNTech abbia mai valutato il potenziale rischio di sicurezza della risposta autoimmune causata dall’uridina modificata o dalle proteine tradotte (oltre alla proteina spike), perché ad agosto 2021, con la data di scadenza di luglio 2021, non è stato ancora fatto. (Si veda l’istantanea qui sotto, a pagina 13 del rapporto CHMP dell’EMA dell’agosto 2021)

Ciò che è preoccupante sono i risultati del più grande studio di questo tipo condotto dal King Fahad University Hospital di Khobar, in Arabia Saudita, che collega i vaccini a mRNA allo scatenamento di malattie autoimmuni, che TrialSite ha riferito di recente. il “mimetismo molecolare”, indicato come preoccupazione nel rapporto dell’EMA di cui sopra, è la stessa ipotesi avanzata nello studio come meccanismo associato ai vaccini a mRNA che causano un processo autoimmune.
Potenziali problemi derivanti dal processo di produzione
La figura seguente mostra la visione semplicistica utilizzata per promuovere il funzionamento dei vaccini a mRNA.
In realtà, il processo è molto variabile e genera a sua volta prodotti proteici molto variabili (vedi figura seguente).

Ogni fase del processo di produzione può introdurre impurità ed errori sconosciuti, dalla traduzione “infedele” del DNA ottimizzato per i codoni, che può generare frammenti di mRNA (non integri), alla trascrizione “infedele” della miscela di mRNA nel corpo umano, che può generare prodotti proteici inaspettati.
McKernan ha poi spiegato ulteriormente il tasso di errore e le sue implicazioni: secondo le mie stime, c’è un errore su ogni singola molecola del vaccino – considerando che ci sono 14 trilioni di molecole in ogni iniezione – non sappiamo cosa significhi dal punto di vista immunologico. Questo è il motivo per cui è necessario un sequenziamento da un lotto all’altro prima di iniettare un prodotto noto per la produzione di nuove proteine all’interno degli esseri umani“
L’mRNA modificato a lunghezza completa del vaccino Pfizer-BioNTech che codifica per la proteina spike è lungo ∼4300 nucleotidi, nt. Tutto ciò che è inferiore a questa lunghezza è considerato una specie di mRNA frammentato, che l’EMA ha classificato come “impurità legata al prodotto”. Questo porta a un altro scandalo, quello noto come Humpgate.
Lo scandalo Humpgate
L’Humpgate può essere considerato il precursore del Blotgate. Mentre il Blotgate si concentrava principalmente sulle bande proteiche dall’aspetto falso espresse dall’mRNA vaccinale visto nei Western di BioNTech, l’Humpgate si riferisce alle specie di mRNA tronche segnalate dall’EMA e da altre autorità di regolamentazione. Il nome deriva dalle “gobbe” che si vedono nell’immagine del post sui social media qui sotto.
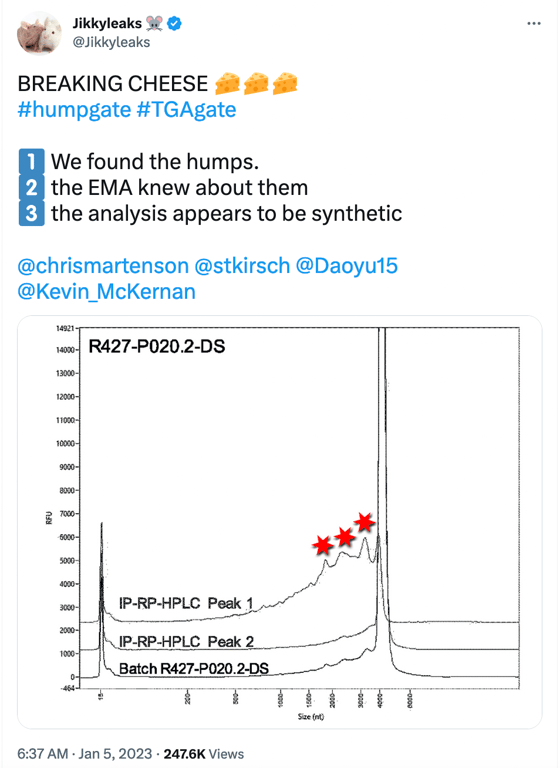
Le 3 “gobbe” indicate dalle stelle rosse rappresentano le specie di RNA troncate/frammentate con una lunghezza ridotta (nt) <4000nt. L’immagine qui sopra è un elettroferogramma del Fragment Analyser (che è l’immagine superiore della Figura 2 mostrata qui sotto) tratto dalla pagina 15 del rapporto redatto dall’EMA nell’estate del 2021, che BioNTech ha intrapreso per soddisfare l’SO1 (obbligo specifico 1) stabilito dall’EMA, che ha richiesto dati aggiuntivi per caratterizzare ulteriormente le specie di mRNA troncate e modificate.

Sono stati prelevati campioni frazionati dal Processo 1(R427-P020.2-DS, lotto di sperimentazione clinica, immagine in alto) e dal Processo 2(20Y513C501, lotto PPQ, immagine in basso) utilizzando l’accoppiamento ionico RP-HPLC per caratterizzare ulteriormente le specie di mRNA intatte (a lunghezza completa) e frammentate. Entrambi i lotti (Processo 1 e 2) mostrano piccole gobbe che portano a un grande picco di circa 4300 nt, che rappresenta la specie di mRNA a lunghezza completa. La linea del grafico etichettata come Picco 1 mostra il materiale “purificato” rianalizzato che comprende solo le specie di mRNA frammentate (queste sono le piccole gobbe che si vedono sul lato sinistro del grande picco a circa 4300 nt del campione del lotto) e il Picco 2 è il materiale “purificato” rianalizzato che comprende le specie di mRNA intatte, viste nel “grande picco”
Questo stesso elettroferogramma si trova nell’articolo di Patel et al. pubblicato nel gennaio 2023 (vedi immagine sotto, pubblicata 18 mesi dopo il rapporto dell’EMA). Eppure, gli autori di Patel et al. citano la loro ricerca come attuale, quando invece si tratta di una versione rielaborata della risposta di Pfizer/BioNTech alle richieste di FDA ed EMA di 18 mesi fa. Il fatto che gli autori abbiano presentato il loro studio come “indipendente” e “attuale”, quando la tecnologia ProteinSimple Wes utilizzata nella loro ricerca è stata interrotta a partire dal 30 luglio 2021, è a dir poco insincero.
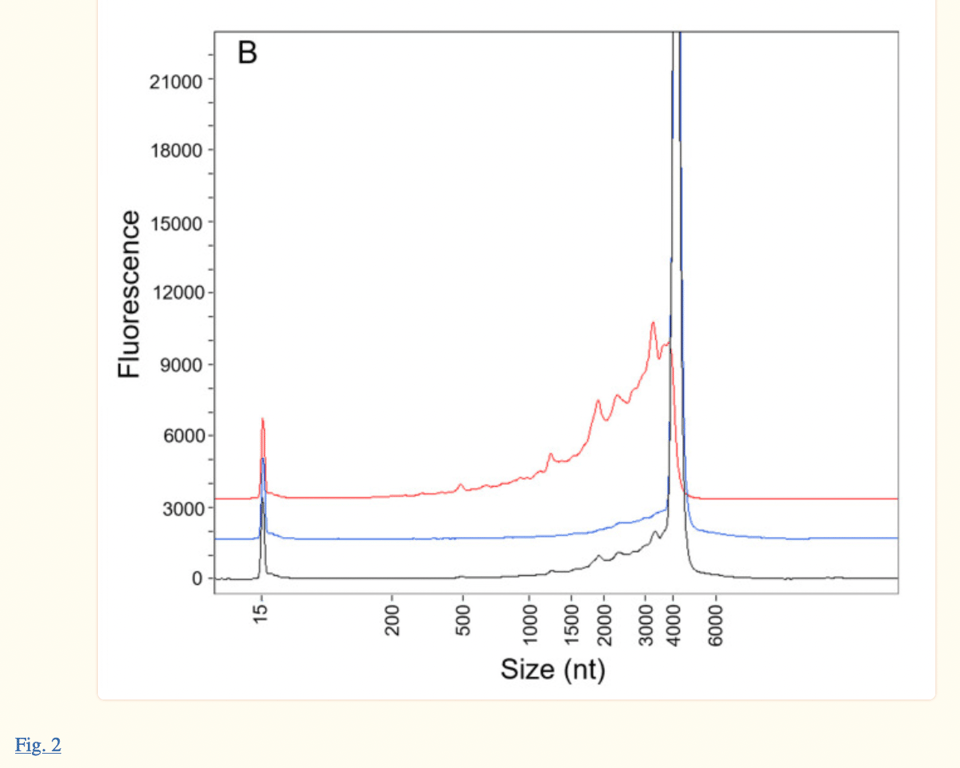
Sia l’articolo di Patel et al. che il documento dell’EMA fanno luce sulle gobbe osservate sul lato sinistro del picco principale a circa 4300 nt. Nella relazione dell’EMA si legge: “La Figura 2 dimostra che il picco 1 è costituito quasi interamente da specie frammentate, in linea con i dati forniti in precedenza nella Valutazione della risposta al CHMP Q01-Quality 11-dic-2020”
Il problema dell’ipotesi di BioNTech
Il modo in cui BioNTech ha assicurato all’EMA che queste specie di RNA troncate non sarebbero state in grado di supportare la traduzione di proteine, per cui le specie troncate viste come “gobbe” negli elettroferogrammi non sarebbero state considerate un problema, è stato quello di condurre ulteriori test Western Blot per dimostrare che l’RNA “trascritto richiede sia il 5′-cap che la poli (A) per supportare la traduzione di proteine”

Questo è l’aspetto di un RNA BNT162b2 completo. All’inizio del trascritto dell’RNA viene aggiunto un cappuccio 5′ e alla fine viene aggiunta una coda 3′ di poli-A. I ribosomi leggono il trascritto da 5′ a 3′.

Le figure seguenti (6 e 5) sono tratte dal rapporto CHMP dell’EMA dell’agosto 2021.

Le corsie vuote mostrate nei pannelli delle sostanze stupefacenti non poly (A) erano sufficienti a dimostrare all’ente regolatorio che l’RNA privo di poly (A) non sarebbe stato in grado di esprimere la proteina spike S1S2. Tuttavia, il problema di questo test è che non conferma che altre proteine aberranti (preoccupazione iniziale dell’EMA) possano essere espresse da questo RNA troncato, poiché sono stati utilizzati solo gli anticorpi di rilevamento specifici per i domini S1 e S2. Il Western Blot mostrato di seguito presenta lo stesso problema. Questo test è stato utilizzato per rassicurare il regolatore sul fatto che l’RNA trascritto privo del 5’cap non sarebbe stato in grado di esprimere la proteina spike S1S2.
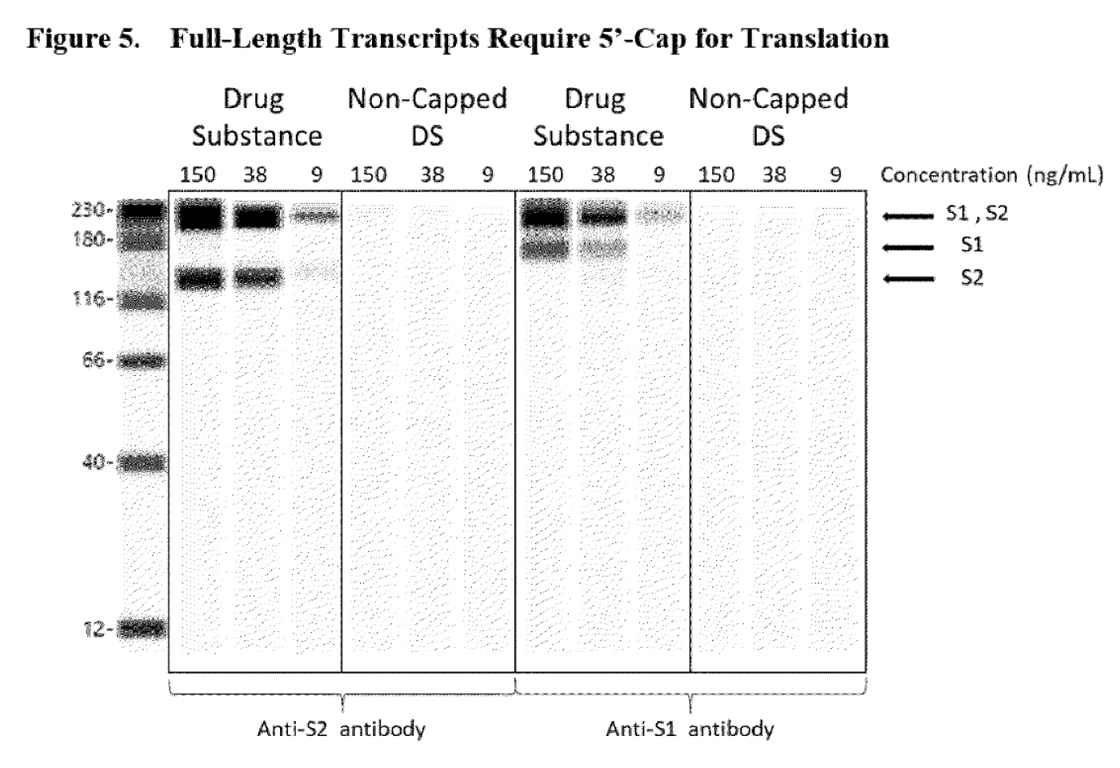
Inoltre, si è ipotizzato che le specie di RNA frammentate fossero il risultato di arresti trascrizionali prematuri o dell’idrolisi dell’mRNA (quando una molecola viene spezzata in due parti quando reagisce con l’acqua), si veda l’estratto sottostante.
la valutazione della sicurezza associata ha rivelato che la probabilità di specie frammentate è generata da arresti trascrizionali prematuri o dall’idrolisi dell’mRNA. Di conseguenza, le specie frammentate non presentano prevalentemente elementi di coda 5′-cap e poli (A) necessari per l’espressione delle proteine”
Fonte: Rapporto del CHMP dell’EMA dell’agosto 2021
Ciò ha dato una falsa sensazione di certezza che un trascritto di mRNA troncato potesse avere solo il 5’cap o la coda di poli (A), ma mai entrambi.
Il miraggio del saggio di degradazione
Il potenziale dei trascritti di RNA troncati di produrre proteine è stato ulteriormente studiato da BioNTech su richiesta dell’ente regolatore. L’aspetto interessante è che il lotto (1071509) è stato appositamente selezionato e intenzionalmente degradato mediante esposizione a temperature elevate, al fine di generare campioni con specie frammentate. Il Western Blot mostrato di seguito è il secondo tradizionale presentato da BioNTech. Mostra che la capacità del trascritto di RNA (quando viene degradato dal calore, quindi frammentato) di esprimere una proteina si riduce.
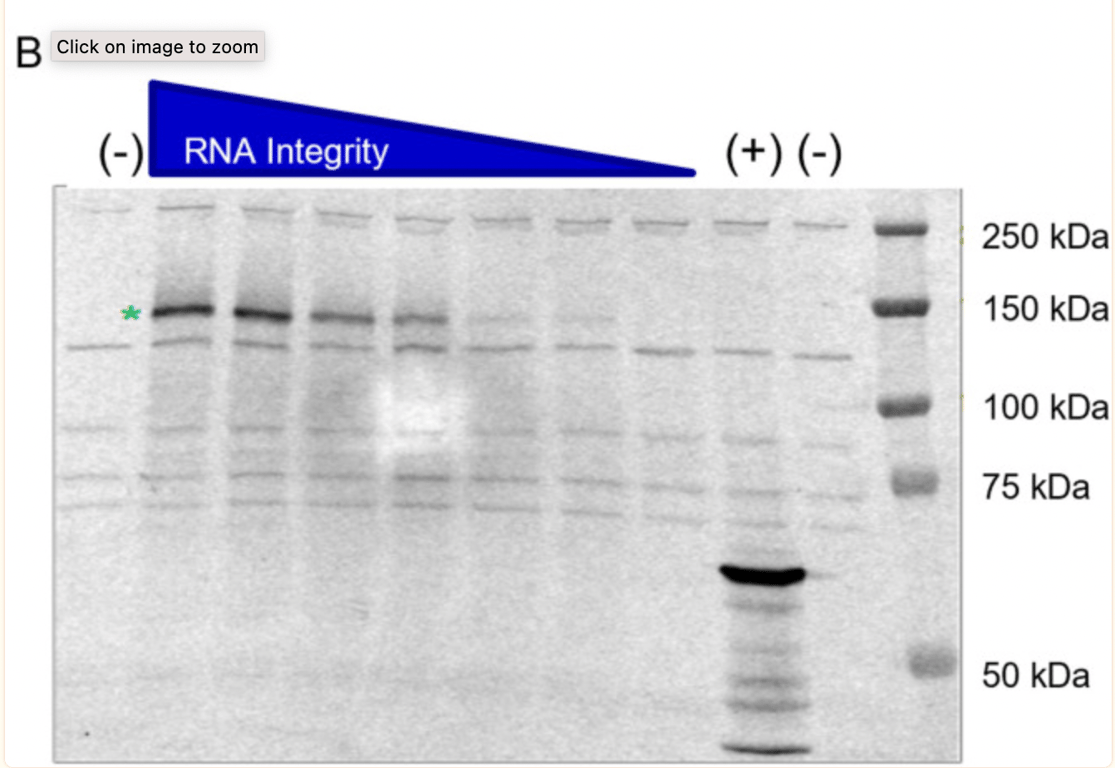
La stella verde mostra che il campione BNT162b2 non degradato (senza riscaldamento, RNA intatto/ad alta integrità) ha prodotto una proteina di circa 140kDa, coerente con le dimensioni previste della proteina aglicosilata S1S2. BioNTech afferma che “non sono state rilevate specie proteiche tronche o di altro tipo oltre alle bande di fondo osservate nel campione di controllo negativo”, tuttavia, nella corsia del campione non degradato, sono visibili bande proteiche e non viene fornita alcuna spiegazione su cosa siano.
Nell’intervista McKernon ha spiegato: “Nel loro studio hanno preso l’mRNA e non l’hanno frammentato come avviene nel processo di produzione, ma l’hanno riscaldato! Il motivo per cui sono frammentati è che le polimerasi si bloccano su queste basi non native (modificate) nel sintetizzare l’RNA, per cui si ottengono questi tratti più corti di RNA nel processo di produzione e questo processo probabilmente varia in base ai nucleotidi che ottengono dai loro fornitori”
Nel rapporto dell’EMA dell’agosto 2021 è stato imposto un nuovo obbligo a BioNTech: la richiesta di eseguire lo stesso esercizio di caratterizzazione per almeno altri tre lotti di tozinameran (mRNA modificato, sostanza farmacologica). Come si può vedere, tale richiesta non è stata soddisfatta entro l’agosto 2021.

E secondo l’ultimo aggiornamento (2 febbraio 2023) del rapporto Comirnaty: EPAR, questo obbligo non è ancora stato rispettato.

McKernan ha anche fatto riferimento all’articolo di Patterson et al. che, in modo allarmante, ha trovato versioni mutate della proteina spike nei soggetti vaccinati che non esistevano nei soggetti non vaccinati che avevano la COVID-19. Questi dati possono essere considerati come dati osservativi reali che dimostrano che versioni mutate (aberranti) della proteina spike vengono tradotte dall’mRNA modificato dal vaccino.
Nel suo commento finale, McKernan ha dichiarato: “I regolatori sono addormentati al volante. Hanno abbandonato il timone e hanno lasciato che questo andasse avanti con il cruise control”
Non potrei essere più d’accordo.
Pubblicato originariamente su Trial Site News
Suggerisci una correzione